Logging (Aries)
1 Durability–Why we need Logging
Let’s first consider a NaiveDB,
-step 1: Admit one transaction T
-step 2: Execute T to completion
-step 3: Atomically flush T’s writes to disk
-step 4: Admit the next transaction
That’s easy. But what if, at some point, the disk/memory/CPU/server crashed down, or I cut down the power? To avoid bad things happening, we need to make database Durability: Once a transaction commits, its effects must be persistent; the DBMS can tolerate systems failures.
Durability: The database must recover to a valid state no matter when a crash occurs.
- Committed transactions should persist.
- Uncommitted transactions should roll back.

2 WAL
To reach durability, we introduce a protocol, Write-Ahead Logging(WAL): Flush the log record for an update before the corresponding data page gets to disk; Write all log records for a transaction before commits.
Before making any changes to the actual data or its structures(like a B+ tree), the system first writes those changes to a log. This log is sequentially written, making it fast to append data.
Why we use it?
Data Integrity and Durability: In case of a system crash or power failure, any transactions not permanently written to the data files can be recovered and completed using the log. This ensures that the database remains in a consistent state.
Backup and Point-in-time Recovery: If you have a backup of a database and a subsequent WAL, you can restore the database to any point in time covered by the log. This can be useful for recovering from both catastrophic failures and human errors, like unintended data deletions.
3 Buffer managerment policies
3.1 Steal?
No Steal: Dirty pages stay in DRAM until the transaction commits.
Steal: Dirty pages can be flushed to disk before the transaction commits.
- Ad: other transactions can use the buffer slot in DRAM
- Challenge: systems crashed after flushing dirty pages but before the transaction commits. => Dirty data on disk!
- Solution: UNDO logging before each update
3.2 Force?
Force: All dirty pages must be flushed when the transaction commits.
No force: Dirty pages may stay in memory after the transaction commits.
- Ad: reduce #random IO(high!)
- Challenge: system crashes after the transaction commits but before the dirty pages are flushed => missing updates from committed transactions!
- Solution: REDO logging before each update.
Notice: the reason choose logging, is that flushing logs can be much cheaper than flushing data pages. Log record can be much smaller than a data page; Logging incurs sequential IO; data page updates incur random IO.
3.3 Policy: How to choose?
Let’s make a table,
3.3.1 Force && No Steal
We start with the easiest one.
It is the most strict policy. We do not write logs before the transaction is committed and force flushing logs to disk when the transaction is committed.
When the system crashes, every committed transactions must persist to disk and every uncommitted transactions must not persist on disk. So we do nothing, NO REDO nor NO UNDO. (Philip Bernstein, Vassos Hadzilacos, Nathan Goodman, Concurrency Control and Recovery in Database Systems, 1987)
3.3.2 Force && Steal
We allow system write logs before the transaction is committed, but force flushing logs to disk when the transaction is committed.
Log UNDO record before each update to database; Log COMMIT record when a transaction finishes execution. Modified data pages can be written to disk after the corresponding UNDO record but before the COMMIT record.
So we do UNDO only (NVM-based database), UNDO uncommitted transactions.
3.3.3 No Force && No Steal
We do not allow system write logs to disk before the transaction is committed, but do not force flushing logs to disk when the transaction is committed.
Log REDO record before each update to database. Log COMMIT record when a transaction finishes execution. Modified data pages can be written to disk after COMMIT record is logged.
So, we replay REDO logs for comitted transactions.
3.3.4 No force && Steal
We not only allow system write logs to dish before the transaction is committed, but also do not force flushing logs to dish when the transaction is committed. The most flexible!
Log combined REDO/UNDO record before each update to database; Log COMMIT record when a transaction finishes execution; Modified data pages can be written to disk any time after the corresponding REDO/UNDO records.
So, we UNDO uncommitted transactions and REDO committed transactions.
3.4 ARIES–A No force && Steal Procotol
Mohan, C., Haderle, D., Lindsay, B., Pirahesh, H., & Schwarz, P. (1992). ARIES: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging. ACM Transactions on Database Systems (TODS), 17(1), 94-162.
3.4.1 Baseline Design
Let’s start with an easiest thinking.
We want to forward scan of entire log: redo all records; keep a table for active transactions. We backward scan of entire log: undo uncommitted transactions. So we introduce data structures like this:

LSN here refers to Log Sequence Number, which can consider as a kind of unique ID.
But it is inefficiency in the REDO process. Unnecessary to redo all records; Need to redo only records that are not reflected in data pages.
It is also inefficiency in the UNDO process. Unnecessary to scan the entire log; Need to undo only records of uncommitted transactions.
It also lack of checkpointing. Unnecessary to start from the beginning of log; Start with the first log record that is not reflected in data pages.
Let’s optimized one by one.
3.4.2 Optimize REDO process
- pageLSN: LSN of the log record that describes the latest update to the pate.
- in REDO scan: Apply REDO only if
record.LSN > page.page.LSN. - Write: update
pageLSN(for the buffered page) for each write.
The new data structure is like below:
3.4.3 Optimize UNDO process
prevLSN: preceding log record written by the same transaction.lastLSN: LSN of the last log record written by the transaction.- UNDO scan: Follow
lastLSNandprevLSNto undo records. - REDO scan: update
lastLSNinTransaction Tablebased on the last update of the transaction.
The new data structure is like below:
3.4.4 Add Checkpoint
pageID: ID of a dirty pagerecLSN: LSN of the first log record since when the page is dirty- Fuzzy Checkpoing: log DPT and TT async.
- REDO scan: start from the smallest LSN in DP.
3.4.5 Compensation Log Record(CLR)
The action of applying UNDO leads to a CLR.
- In undo scan, do not reapply UNDO if CLR exists. Do not UNDO a UNDO operation
UndoNxtLSN: LSN of the next record to be processed during the undo scan.
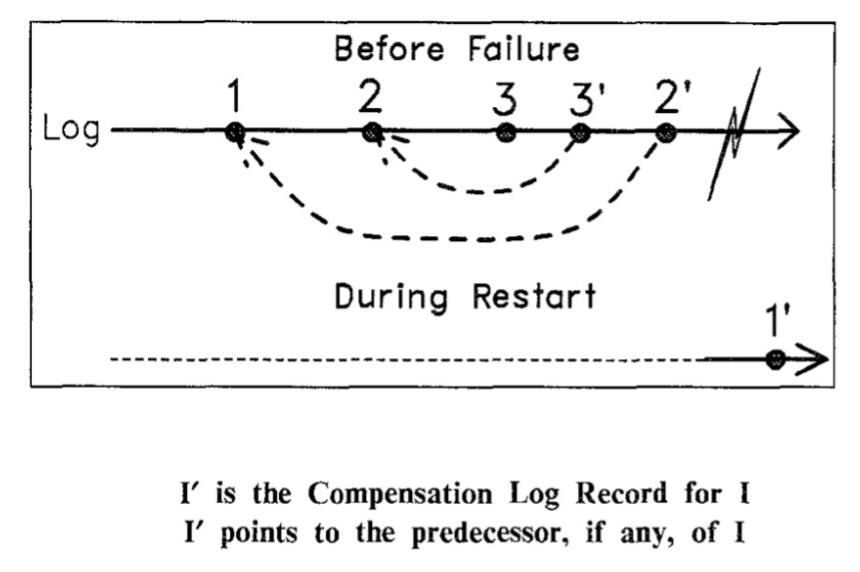
This is because:
- Avoid Infinite Loops: If the system kept reapplying the UNDO for a CLR, it would enter into an infinite loop. This is because when you undo a CLR, you’d create another CLR to compensate for that, and then undo that CLR, creating yet another CLR, and so on.
- CLR Represents an Undo: The very existence of a CLR for a log record indicates that the effects of the original log record have already been undone. Reapplying the UNDO would be redundant and unnecessary.
- Consistency & Idempotence: One of the primary design goals of recovery algorithms like ARIES is to ensure that the recovery actions are idempotent. That means you can apply them multiple times and still achieve the same state. If you were to reapply the UNDO for a CLR, this idempotent property could be violated.
The new data structure is like below:
3.4.6 ARIES-Big Picture
Start from the last complete checkpoint.
- Analysis phase:
1.1 rebuild transaction table (for undo phase): for each log record, ifupdateorCLR, insert to transaction table if not exists; ifend, delete from transaction table
1.2 rebuild dirty page table (for redo phase): ifupdateorCLR, insert to dirty page table if not exists - REDO phase:
redo transactions whose effects may not be persistent before the crash
2.1 From log record containing smallestRecLSNin the dirty page table. Before this LSN, all redo records have been reflected in data pages on disk.
2.2 Can skip a redo record for the following cases where the corresponding page has already been flushed before the crash. The page is not in DPT; The page is in DPT butredo_record.LSN<DPT[page].recLSN; After fetching the data page,redo_record.LSN<=page.page_LSN. - UNDO phase:
undo transactions that did not commit before the crash
3.1 Choose largestLastLSNamong transactions in the TT.
3.2 If the log record is anupdate, UNDO the update, write aCLR, addrecord.prevLSNto TT.
3.3 if the log record is anCLR, addCLR.UndoNxtLsnto TT.
3.4 IfprevLSNandUndoNxtLSNareNULL, remove the transaction from TT.

3.4.7 Example
Let’s consider a situation
Analysis phase start at checkpoint
step 1:
step 2:
Step 3:
Step 4:
Step 5:
REDO phase with given data pages
Step 1:
Step 2:
Step 3:
Step 4:
Step 5:
UNDO phase
Step 1:
Step 2:
Step 3:
Step 4: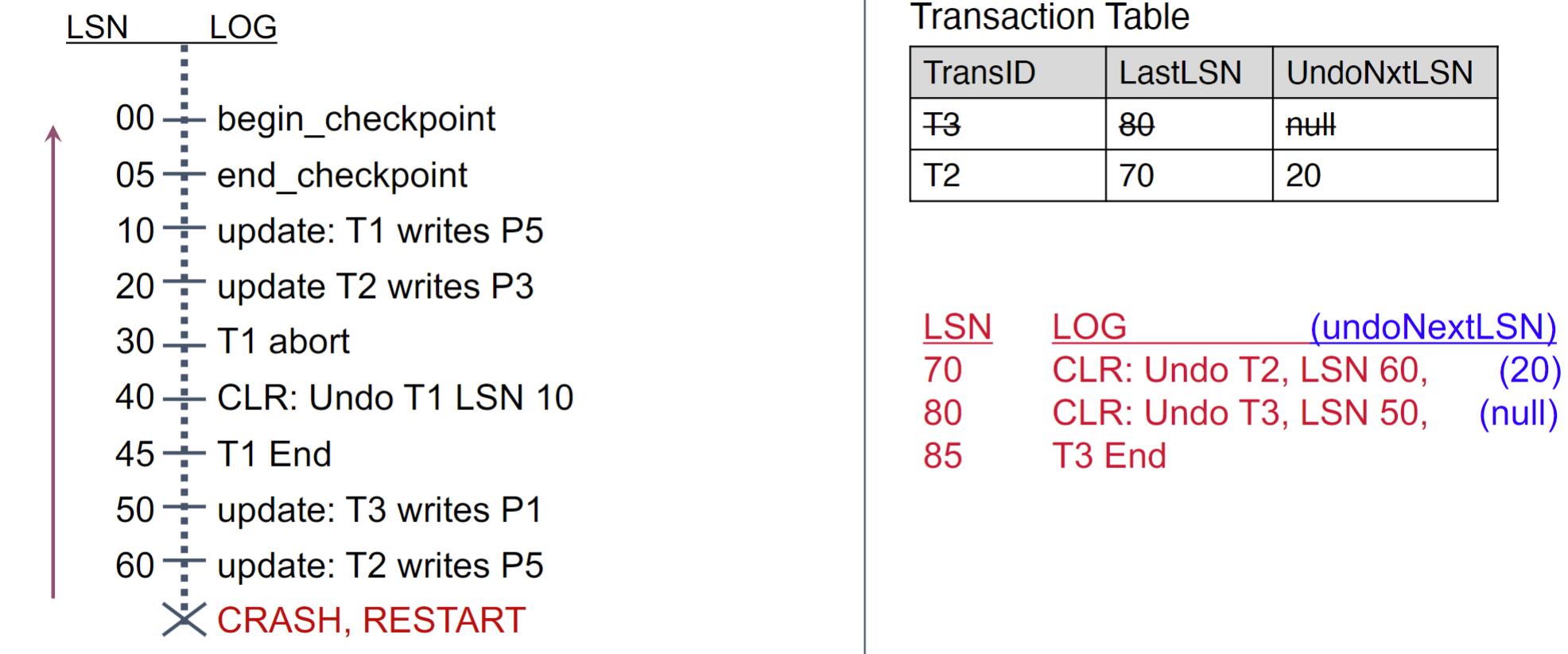
Step 5:
Step 6:
4 Acknowledgement
Thanks UW-Madison COMP 564 Prof Xiangyao Yu!