Amazon Aurora
Paper
Verbitski, A., Gupta, A., Saha, D., Brahmadesam, M., Gupta, K., Mittal, R., … & Bao, X. (2017, May). Amazon aurora: Design considerations for high throughput cloud-native relational databases. In Proceedings of the 2017 ACM International Conference on Management of Data (pp. 1041-1052).
1 How to Reach Durability
1.1 Quorum-Based Voting Protocol
Suppose in a replicated system has $V$ copies, each one assigned a vote. A read or write operation must respectively obtain a read quorum of $V_{r}$ votes or a write quorum of $V_{w}$ votes. We need
$$ V_r + V_w > V $$
$$ V_w > V/2 $$
For the first formula, each read must be aware of the most recent write. It ensures that any read operation overlaps with any write operation. This means that for any read to be completed, it must involve at least one node that participated in the most recent write.
For the second formula, each write must be aware of the most recent write. It ensures that no two write operations can be completed concurrently without overlapping. Since a majority of votes is required for a write operation to succeed, there can never be two separate majorities simultaneously. This means that before a new write can take place, the latest information must be disseminated to the majority of nodes.
Available Zone(AZ): a connected to other AZs through low latency links but is isolated for most faults. -> fail independantly.
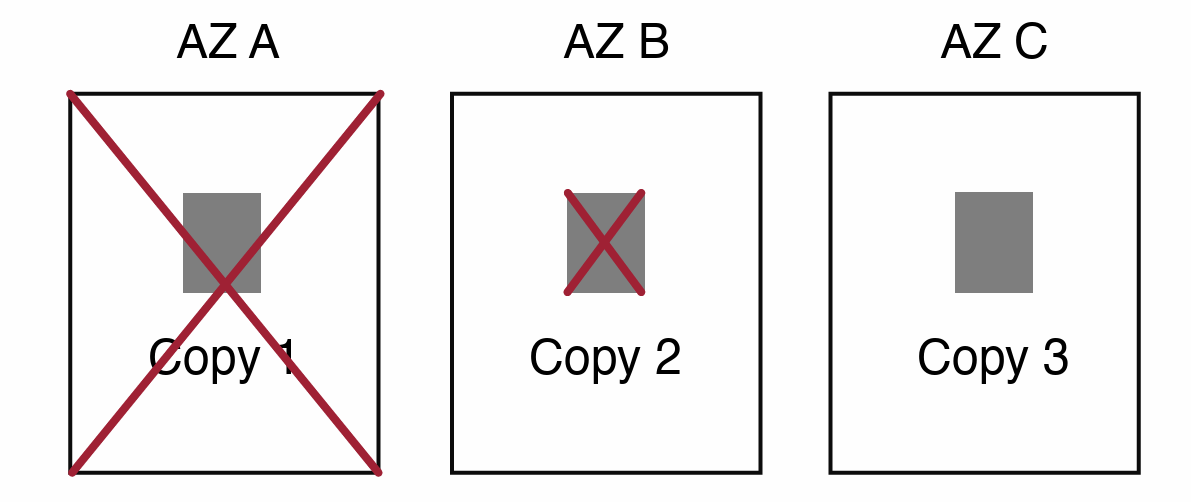
A common example of three copies: $ V_w \geq 2$, $ V_r \geq 2$. Data is unavailable if one AZ is unavailable and one other copy is unavailable.
However, this might be inadequate. If an entire AZ goes down due to a large-scale event like a fire or flood, it doesn’t just take down one node but potentially a whole set of nodes that are part of the quorum. In a 2/3 quorum system, if two AZs were to experience failures concurrently, the system would lose access to two-thirds of its nodes, and it would be impossible to complete any operations because database wouldn’t have enough nodes to form a quorum. The system’s requirement is that at least two nodes must be available and agree on the state of the data to maintain consistency and availability.
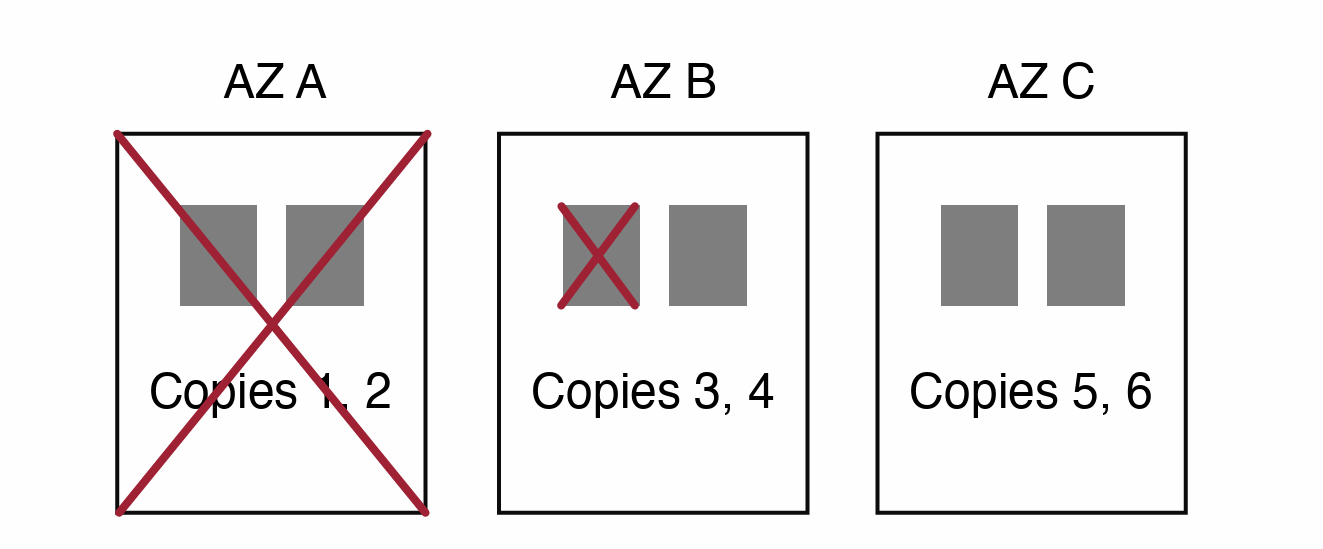
Thus, in Aurora practice, they pick six copies across three AZs: $V_w \geq 4$, $V_r \geq 3$. Can read if one AZ fails and one more copy fails. Can write if one AZ fails.
1.2 Segmented Storage
MTTF: Mean Time to Failure
MTTR: Mean time to Repair
MTTF is commonly hard to reduce, Aurora focus on minimize MTTR to prevent double fault(which will lead to quorum failure).
Aurora do so by partitioning the database volume into small fixed Segments, 10GB block, basic unit of failure and repair. These are each replicated 6 ways (organized across 3 AZs) into Protection Groups(PGs) so that each PG consists of six 10 GB segments.
2 How to Leverage Smart Storage
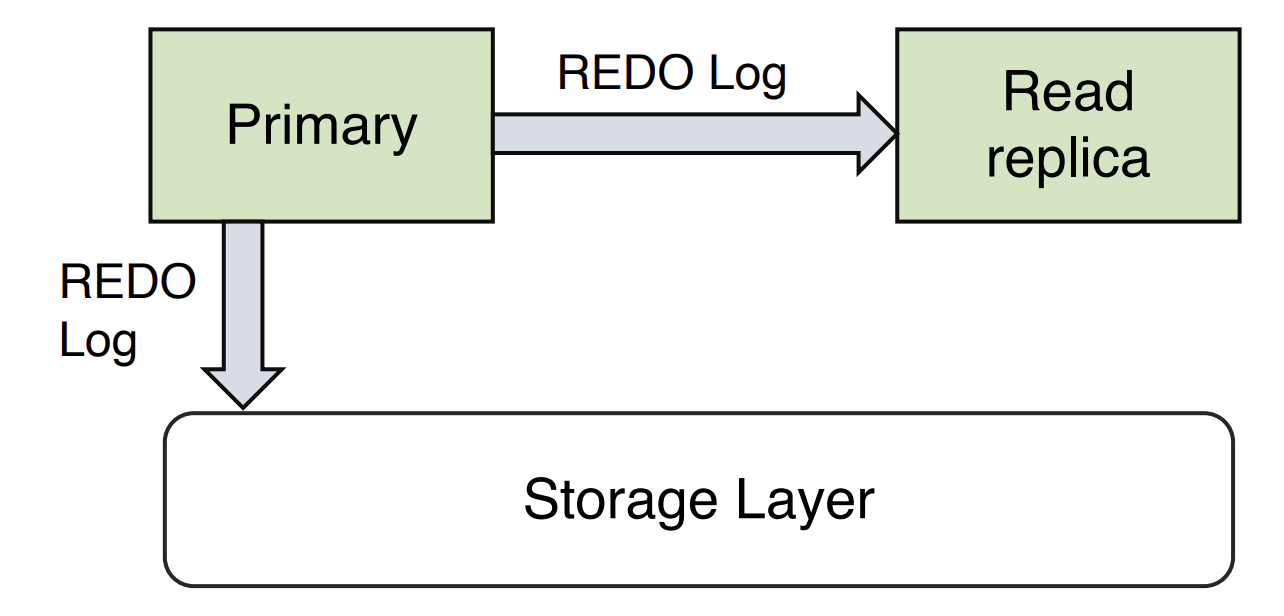
2.1 MySQL Network I/O Limitation
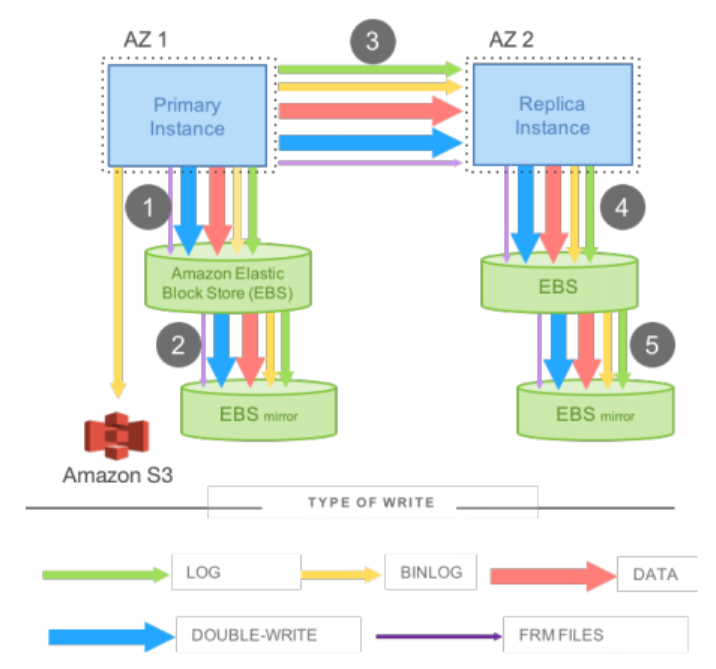
- (REDO) log: generated by InnoDB, is physical
- Binlog: generated by MySQL and supportes other storage engines, can be either physical or logical, in order to support point-in-time restores
- Data: the modified data pages
- Double-write: to prevent torn pages
- metadata(FRM)
Step 1 & 2: writes are issued to EBS, which in turn issues it to an AZ-local mirror, and the acknowledgement is received when both are done
Step 3: the write is staged to the standby instance using sync block-level software mirroring
Step 4 & 5: writes are written to the standby EBS volume and associated mirror
Limitation 1: Steps 1, 3, 5 are sequential and sync
Limitation 2: duplication in multi types of write
2.2 Offloading Redo Processing to Storage
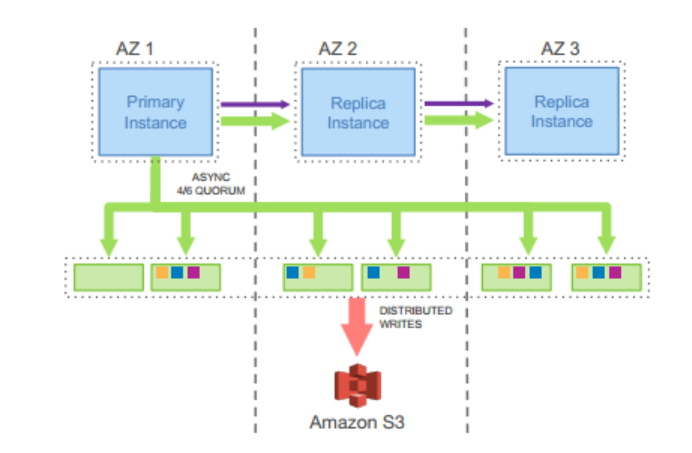
Aurora DB writes only REDO log to storage, the storage layer replays the log into data pages.
It sounds like distributed git, we do not send whole hard data page replica and log, we only send “commits”(log), told everyone the modification. Each replicas can async apply REDO logs to data pages.
How about crash recovery, in a traditional database, after a crash the system must start from the most recent checkpoint and replay the log to ensure that all persisted redo records have been applied. In Aurora, any read request for a data page may require some redo records to be applied if the page is not current. The process of crash recovery is spread across all normal foreground processing. Nothing is required at database startup.
2.3 Aurora Storage Steps
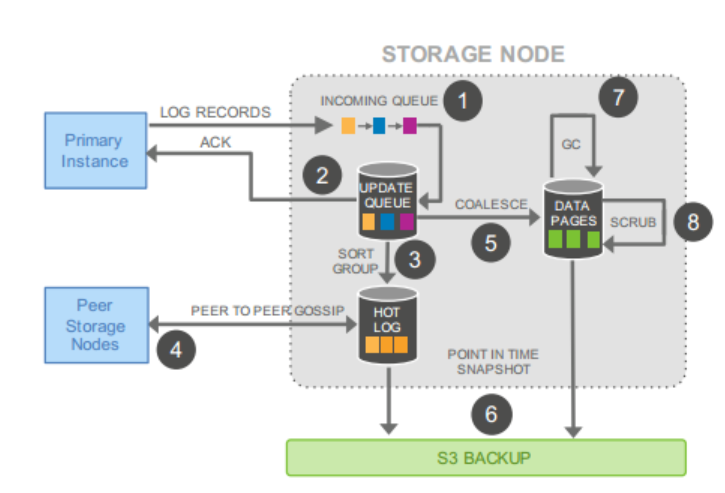
Step 1: receive log record and add to an in-memory queue
Step 2: persist record on disk and acknowledge
Step 3: organize records and identify gaps in the log since some batches may be lost
Step 4: gossip with peers to fill in gaps
Step 5: coalesce log records into new data pages
Step 6: periodically stage log and new pages to S3
Step 7: periodically garbage collect old versions
Step 8: periodically validate CRC codes on page
Each steps are asynchronous, and only step 1 and step 2 are in foreground path potentially impacting latency.
3 Logging forward
3.1 Recovery Correctness
VCL: The storage service determines the highest LSN for which it can guarantee availability of all prior log records VCL(Volume Complete LSN). During the storage recovery, every log record with an LSN larger than the VCL must be truncated.
CPL: Database constrain a subset of points that are allowable for truncation by tagging log records, identify them as CPLs(Consistency Point LSN).
VDL: Volume Durable LSN, the highest CPL that is smaller than or equal to VCL, and database trucate all log records with LSN larger than VDL.
e.t.: even if we have the complete data up to LSN 1007, the database may have declared that only 900, 1000, and 1100 are CPLs, in which case, we must truncate at 1000. We are complete to 1007, but only
durable to 1000.
VDL is smaller than VCL: there are pending transactions that have been logged (and are thus reflected in the VCL) but have not yet been fully committed and marked as durable. Thus, completeness is different from durability, if the client do not use such distinction, it can simply mark every log record as CPL.
Interaction:
- Each database-level transaction is broken up into multiple mini-transactions(MTRs) that are ordered and must be performed atomically.
- Each mini-transaction is composed of multiple contiguous log records(as many as needed).
- The final log record in a mini-transactions is a CPL.
- On recovery, the db talks to the storage PGs and calculate VDL.
3.2 Normal Operation
Write: As the database receives acknowledgements to establish the write quorum for each batch of log records, it advances the current VDL. Database allocates a unique ordered LSN for each log record subject to:
no LSN is greater than the sum of the current VDL and LSN Allocation Limit
Commit: async, as the VDL advances, the database identifies qualifying transactions that are waiting to be committed and uses a dedicated thread to send commmit acknowledgements to waiting clients. That is, when the current VDL is larger than the transaction’s commit LSN.
Reads: offered from the buffer cache, only result in a storage IO request if the page in question is not present in the cache.
- For Traditional, the dirty evicted page will write back to storage.
- For Aurora, the dirty evicted page just through away.
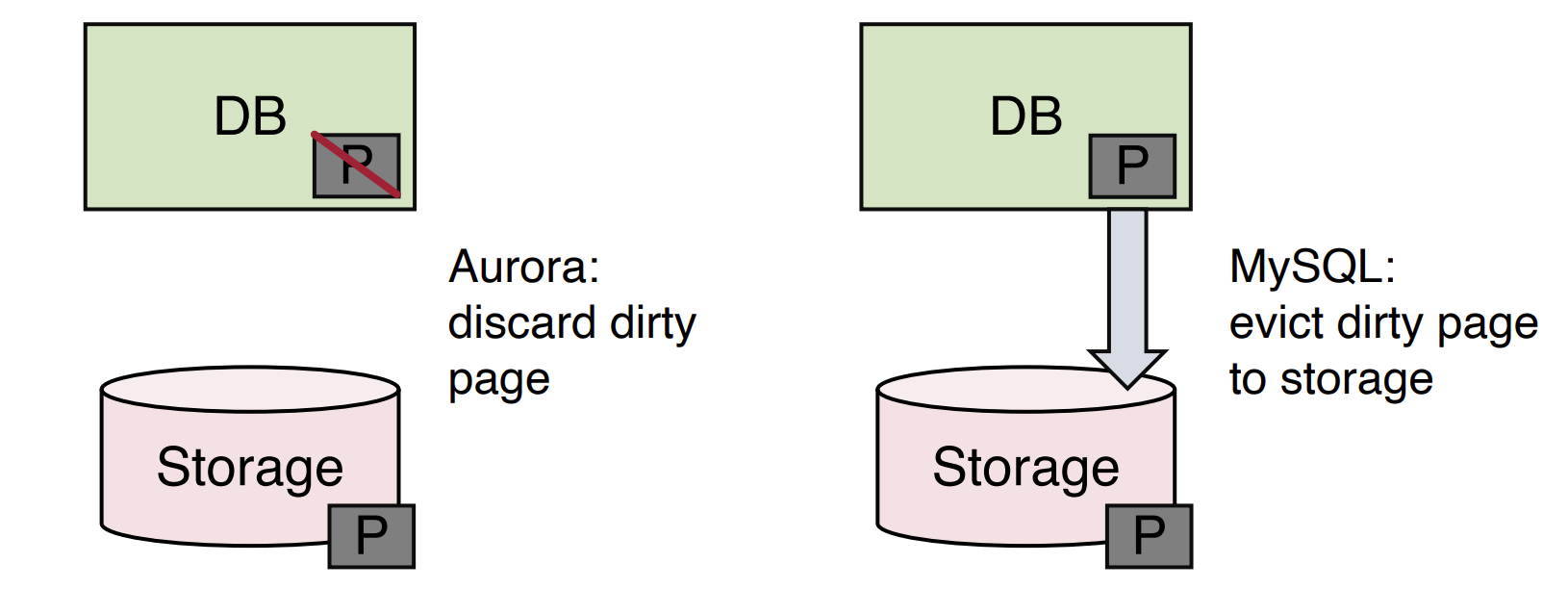
To make sure a page in the buffer cache must always be of the latest version, Aurora evict a page from the cache only if its page LSN is greater than or equal to the VDL.
The DB server knows which node contains the latest value, result a single read from the update-to-date node.
Replication
If page is in replica’s local buffer, update the page, otherwise, discard the log record.
- the only log records that will be applied are those whose LSN is less than or equal to the VDL
- the log records that are part of a single mini-transaction are applied atomically in the replica’s cache to reach consistent